2025-12-15 05:47:49 PM

4 minutes readPublished: 2025-06-29 10:39 PM
What Is Mixture-of-Experts? The Breakthrough Architecture Powering Massive AI Models Like GPT, Mixtral, and Gemini
What is Mixture-of-Experts? This powerful architecture is the backbone of large-scale AI models like GPT, Mixtral, and Gemini. In this article, we explore Mixture-of-Experts (MoE) from a developer’s perspective—tracing its origins, understanding its routing logic, and analyzing how it optimizes compute while scaling model capacity. You'll learn how MoE selectively activates only a few expert networks per input token, dramatically reducing computation cost without sacrificing performance. Through intuitive analogies and technical breakdowns, we’ll walk through how gating networks, top-k routing, and modular feed-forward layers work in harmony to handle complex tasks efficiently. Whether you’re a machine learning engineer, AI researcher, or curious learner, this guide will equip you with foundational knowledge on one of the most transformative concepts in modern model architecture.
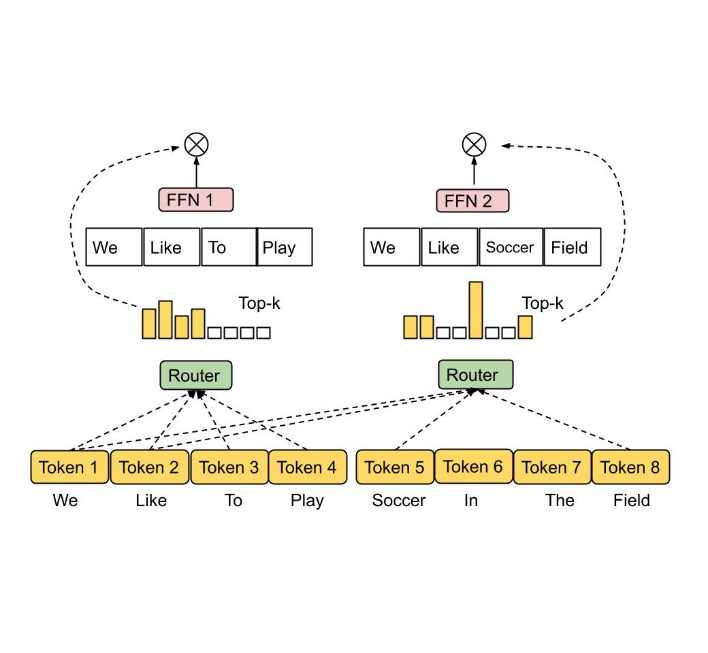
What is Mixture-of-ExpertsMoE explainedMoE AI modelexpert routing in transformersmixture of expert layerstop-k routingGPT MoE architecturegating network AImodular transformer modelstransformer expert layersmixtral moe structureopenai moelarge model routingcompute-efficient transformersmoe in deep learningmixure of expermiutre of expertexpert router modelexpert selection transformerefficient ai architecture

LynxJS: A Comprehensive Solution for Cross-Platform Applications

Important LLM Terms Every Developer Should Know to Optimize Effectively

Guideline No. 12-HD/BTCTW: Comprehensive Content and Key Significance

Unlocking the 12 Zodiac Signs: Traits, Symbols & Meanings Explained Briefly

Left Eye Twitching in Men: Meaning and Causes